機械学習での顔認識
2022年09月09日(金曜日)
■概要
python + scikit-learnを用いて機械学習を行い、
学習したモデルに任意の画像を与え誰に似ているかを推論
■データセットの取得
from sklearn.datasets import fetch_lfw_people
dataset = fetch_lfw_people()
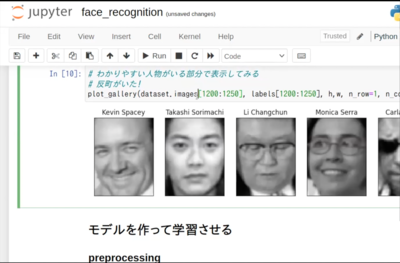
・どんな感じのデータかちょっと見てみる
print(dataset.keys()) 取得したデータセットの内容
■モデルを作って学習させる
・preprocessing(前処理)
可能な限り情報量を減らすことで学習時間が短縮され、精度も向上する
画像データ
→サイズを統一、解像度や色を単純化した上で数値としてベクトル化
自然言語
→出現頻度や位置に応じてインデクス化など、数値としてベクトル化
from sklearn import preprocessing
le = preprocessing.LabelEncoder() ラベルエンコーダーを使用
le.fit(dataset.target_names) 人物名をラベルエンコーダーで処理
人物名をエンコード
transformed_labels = le.transform(labels)
for i in range(0,5):
print(f"label: {transformed_labels[i]},
person name:{le.inverse_transform
([transformed_labels[i]])}")
・モデル作成&学習
from sklearn.model_selection import train_test_split
データを学習用とテスト用に分ける
X_train, X_test, y_train, y_test = train_test_split(
dataset.data,
dataset.target,
test_size=0.25, random_state=20
)
from sklearn import tree
import time
import datetime
決定木アルゴリズムでモデル実装
今回はデフォルト値で実行
model = tree.DecisionTreeClassifier()
start = time.time()
model.fit(X_train, y_train)
end = time.time()
print(f'total training time:
{datetime.timedelta(seconds=end-start)}')
print(model2.loss_)
学習に時間がかかるので保存
import pickle
with open('/srv/app/saved_model/model.pickle', 'wb') as f:
pickle.dump(model, f)
・推論
model読み込み
import pickle
with open('/srv/app/saved_model/model.pickle', 'rb') as f:
model = pickle.load(f)
import pandas as pd
result=[]
corrects=[]
predictions = model.predict(X_test)
for i, prediction in enumerate(predictions):
if labels[int(y_test[i])]==labels[prediction]:
corrects.append(prediction)
result.append({
'fact_index': y_test[i],
'fact_name': labels[int(y_test[i])],
'prediction_index': prediction,
'prediction_name': labels[prediction],
'correct?': labels[int(y_test[i])]==labels[prediction]
})
result_df = pd.DataFrame(result)
→全部で3309件中で推論に成功したのは.....80件!
推論結果種別数: 1576
■まとめ
結論として、このモデルでは全然精度が出ていない
本来であればここからハイパーパラメーターをチューニングしたり
アルゴリズム自体を見直したりと、モデルチューニングをして
精度を追求していく
python + scikit-learnを用いて機械学習を行い、
学習したモデルに任意の画像を与え誰に似ているかを推論
■データセットの取得
from sklearn.datasets import fetch_lfw_people
dataset = fetch_lfw_people()
・どんな感じのデータかちょっと見てみる
print(dataset.keys()) 取得したデータセットの内容
■モデルを作って学習させる
・preprocessing(前処理)
可能な限り情報量を減らすことで学習時間が短縮され、精度も向上する
画像データ
→サイズを統一、解像度や色を単純化した上で数値としてベクトル化
自然言語
→出現頻度や位置に応じてインデクス化など、数値としてベクトル化
from sklearn import preprocessing
le = preprocessing.LabelEncoder() ラベルエンコーダーを使用
le.fit(dataset.target_names) 人物名をラベルエンコーダーで処理
人物名をエンコード
transformed_labels = le.transform(labels)
for i in range(0,5):
print(f"label: {transformed_labels[i]},
person name:{le.inverse_transform
([transformed_labels[i]])}")
・モデル作成&学習
from sklearn.model_selection import train_test_split
データを学習用とテスト用に分ける
X_train, X_test, y_train, y_test = train_test_split(
dataset.data,
dataset.target,
test_size=0.25, random_state=20
)
from sklearn import tree
import time
import datetime
決定木アルゴリズムでモデル実装
今回はデフォルト値で実行
model = tree.DecisionTreeClassifier()
start = time.time()
model.fit(X_train, y_train)
end = time.time()
print(f'total training time:
{datetime.timedelta(seconds=end-start)}')
print(model2.loss_)
学習に時間がかかるので保存
import pickle
with open('/srv/app/saved_model/model.pickle', 'wb') as f:
pickle.dump(model, f)
・推論
model読み込み
import pickle
with open('/srv/app/saved_model/model.pickle', 'rb') as f:
model = pickle.load(f)
import pandas as pd
result=[]
corrects=[]
predictions = model.predict(X_test)
for i, prediction in enumerate(predictions):
if labels[int(y_test[i])]==labels[prediction]:
corrects.append(prediction)
result.append({
'fact_index': y_test[i],
'fact_name': labels[int(y_test[i])],
'prediction_index': prediction,
'prediction_name': labels[prediction],
'correct?': labels[int(y_test[i])]==labels[prediction]
})
result_df = pd.DataFrame(result)
→全部で3309件中で推論に成功したのは.....80件!
推論結果種別数: 1576
■まとめ
結論として、このモデルでは全然精度が出ていない
本来であればここからハイパーパラメーターをチューニングしたり
アルゴリズム自体を見直したりと、モデルチューニングをして
精度を追求していく
